Scaling with Queues
Last Updated: Sep 2, 2013Our home-grown geo-distributed architecture based CDN allows us to delivery dynamic javascript content with minimum latencies possible. Using the same architecture we do data acquisition as well. Over the years we’ve done a lot of changes to our backend, this post talks about some scaling and reliability aspects and our recent work on making fast and reliable data acquisition system using message queues which is in production for about three months now. I’ll start by giving some background on our previous architecture.
Web beacons are widely used to do data
acquisition, the idea is to have a webpage send us data using an HTTP request
and the server sends some valid object. There are many ways to do this. To keep
the size of the returned object small, for every HTTP request we
return a tiny 1x1 pixel gif image and our geo-distributed architecture along with
our managed Anycast DNS service helps us to do this with very low latencies,
we aim for less than 40ms. When an HTTP request hits one of our data acquisition servers, OpenResty
handles it and our Lua based code processes the request in the same process thread.
OpenResty is a nginx mod which among many things bundles luajit that allows
us to write URL handlers in Lua and the code runs within the web server. Our Lua code
does some quick checks, transformations and writes the data to a Redis
server which is used as fast in-memory data sink. The data stored in Redis is
later moved, processed and stored in our database servers.
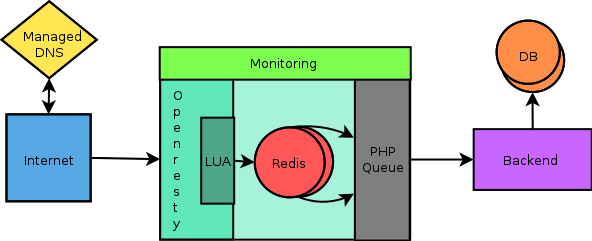
Previous Architecture
This was the architecture when I had joined Wingify couple of months ago. Things were going smooth but the problem was we were not quite sure about data accuracy and scalability. We used Redis as a fast in-memory data storage sink, which our custom written PHP based queue infrastructure would read from, our backend would process it and write to our database servers. The PHP code was not scalable and after about a week of hacking, exploring options we found few bottlenecks and decided to re-do the backend queue infrastructure.
We explored many options and decided to use RabbitMQ. We wrote a few proof-of-concept backend programs in Go, Python and PHP and did a lot of testing, benchmarking and real-world load testing.
Ankit, Sparsh and I discussed how we should move forward and we finally decided to explore two models in which we would replace the home-grown PHP queue system with RabbitMQ. In the first model, we wrote directly to RabbitMQ from the Lua code. In the second model, we wrote a transport agent which moved data from Redis to RabbitMQ. And we wrote RabbitMQ consumers in both cases.
There was no Lua-resty library for RabbitMQ, so I wrote one using cosocket APIs
which could publish messages to a RabbitMQ broker over STOMP protocol. The library
lua-resty-rabbitmqstomp was
opensourced for the hacker community.
Later, I rewrote our Lua handler code using this library and ran a loader.io
load test. It failed this model due to very low throughtput,
we performed a load test on a small 1G DigitalOcean instance for both models.
For us, the STOMP protocol
and slow RabbitMQ STOMP adapter were performance bottlenecks. RabbitMQ was not
as fast as Redis, so we decided to keep it and work on the second
model. For our requirements, we wrote a proof-of-concept Redis to RabbitMQ transport
agent called agentredrabbit to leverage Redis as a fast in-memory storage sink and
use RabbitMQ as a reliable broker. The POC worked well in terms of performance,
throughput, scalability and failover. In next few weeks we were able to write a
production level queue based pipeline for our data acquisition system.
For about a month, we ran the new pipeline in production against the existing one, to A/B test our backend :) To do that we modified our Lua code to write to two different Redis lists, the original list was consumed by the existing pipeline, the other was consumed by the new RabbitMQ based pipeline. The consumer would process and write data to a new database. This allowed us to compare realtime data from the two pipelines. During this period we tweaked our implementation a lot, rewrote the producers and consumers thrice and had two major phases of refactoring.
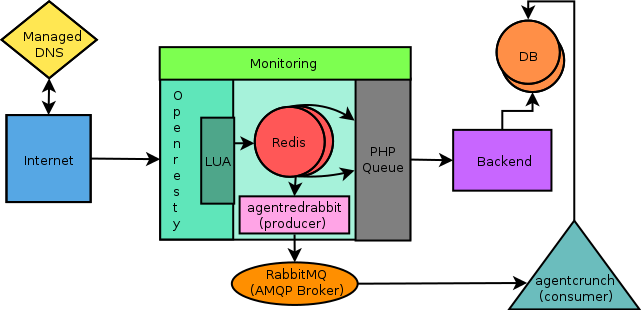
A/B testing of existing and new architecture
Based on results against a 1G DigitalOcean instance like for the first model and against the A/B comparison of existing pipeline in realtime, we migrated to the new pipeline based on RabbitMQ. Other issues of HA, redundancy and failover were addressed in this migration as well. The new architecture ensures no single point of failure and has mechanisms to recover from failure and fault.
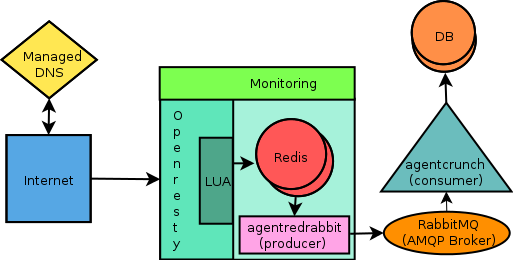
Queue (RabbitMQ) based architecture in production
We’ve opensourced agentredrabbit
which can be used as a general purpose fast and reliable transport agent for
moving data in chunks from Redis lists to RabbitMQ with some assumptions and queue
name conventions. The flow diagram below has hints on how it works, checkout the
README for details.
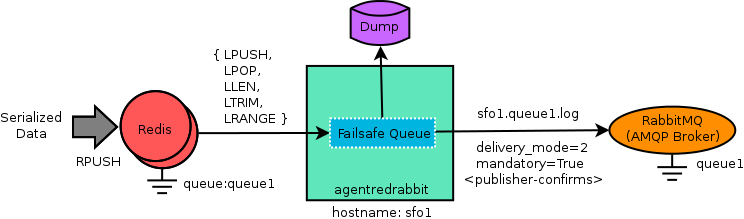
Flow diagram of "agentredrabbit"